Abstract
We present DFormer, a novel RGB-D pretraining framework to learn expressive representations for RGB-D segmentation tasks. DFormer has two new renovations: 1) Unlike previous works that aim to encode RGB features, DFormer comprises a sequence of RGB-D blocks, which are tailored for encoding both RGB and depth information through a novel attention module. 2) We pretrain the backbone using image-depth pairs from ImageNet-1K, and thus the DFormer is endowed with the capacity of encoding RGB-D representations. It avoids the mismatched encoding of the 3D geometry relationships in depth maps by RGB pre-trained backbones, which widely lies in existing methods but has not been resolved. We fine-tune the pre-trained DFormer on two popular RGB-D tasks, i.e., RGB-D semantic segmentation and RGB-D salient object detection, with a lightweight decoder head. Experimental results show that our DFormer achieve a new state-of-the-art performance on these two tasks with lower computation cost compared to previous SOTA methods, e.g., 57.2% mIoU on the NYUv2 dataset with 39.0M parameters and 65.7G Flops.
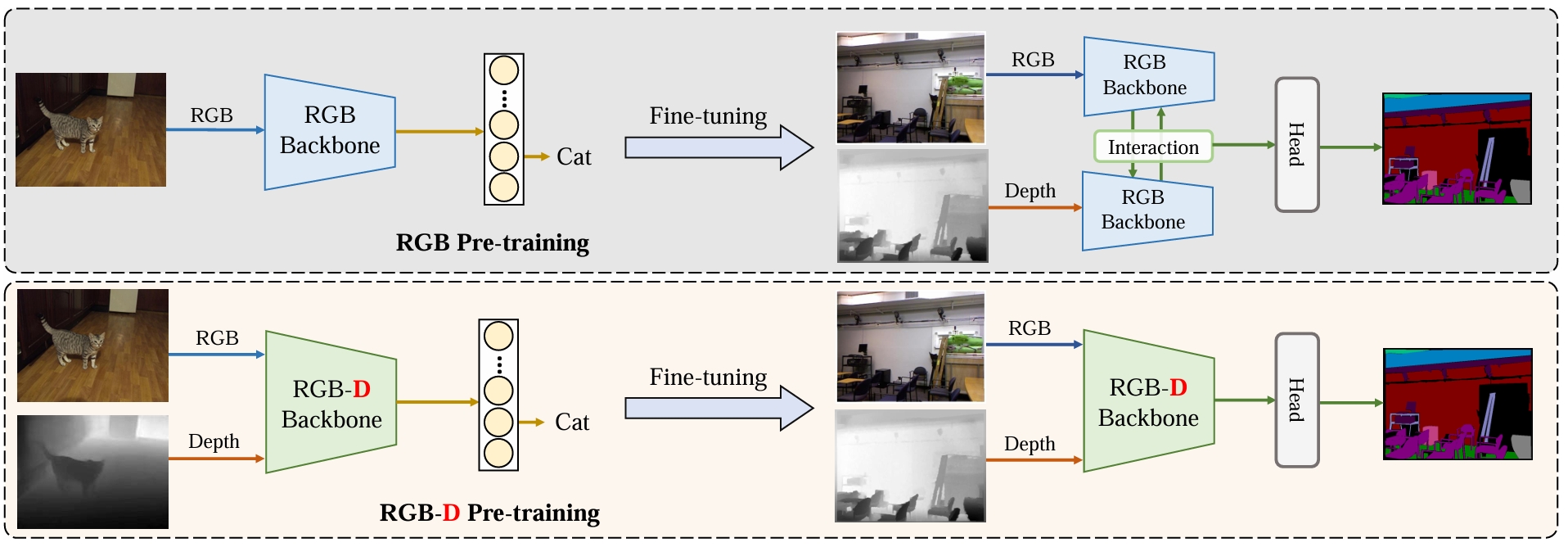
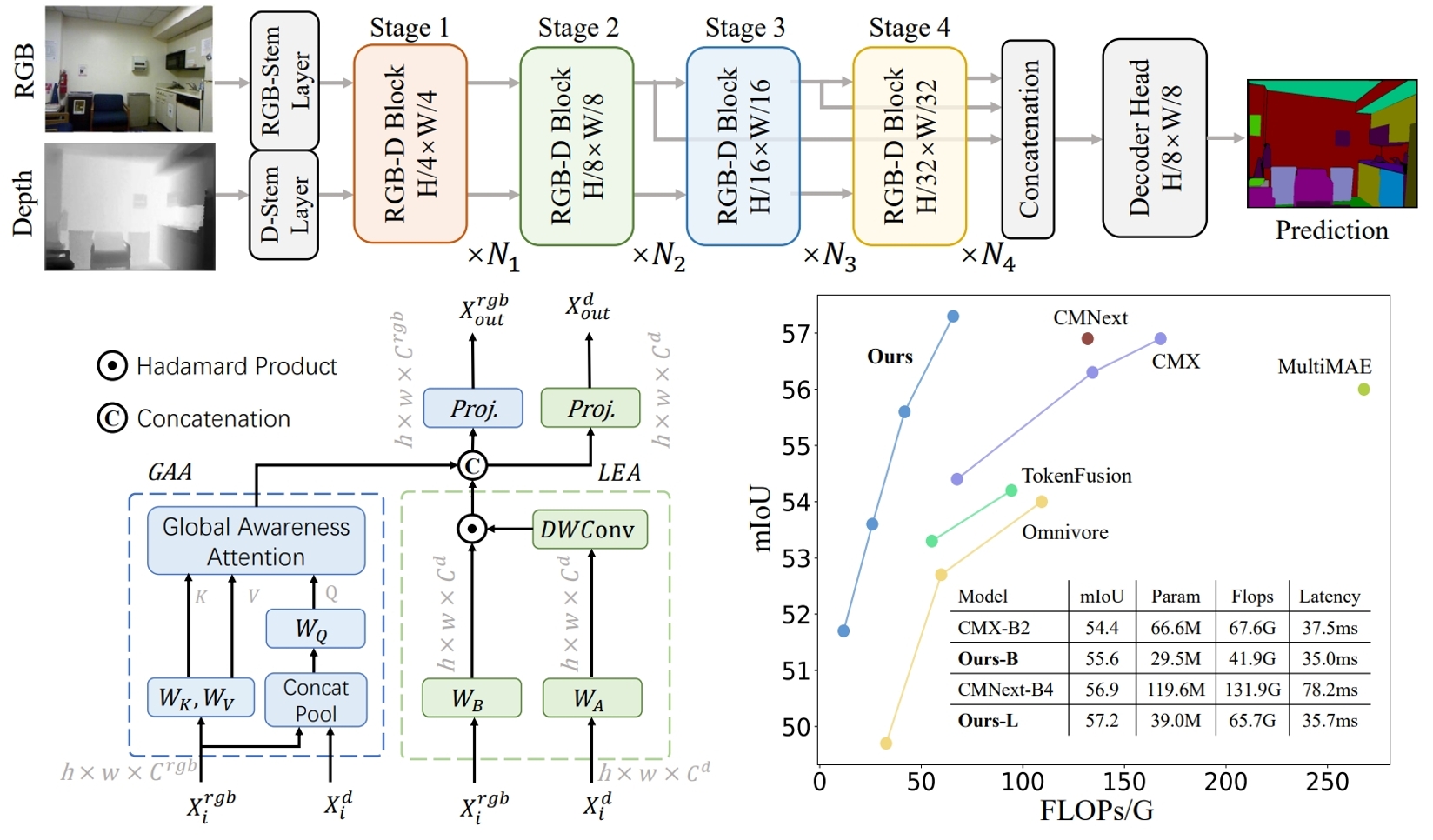
The RGBD pretraining framework in DFormer.